Tag: studying
This page will . . . eventually . . . become very large. It may even breed an equally large family of pages—we’ll have to see about that. Since I have accumulated quite a bit of information about the songwriters, publishers, and all the rest who are present on the sheet music archive, I will shape that which seems interesting to tell, briefly, the stories of each of the people. And that’s what you will find here.
I have been bedazzled by the playground (says Lou Harrison) left to us by Charles Ives for nigh on fifty years, so you would think that this page would be overflowing . . . but it’s not . . . yet . . .
Just another disappointment for you, I’m sure . . and I do apologize . . .
And for Mr. Cage, the news isn’t good, either: there’s nothing here.
But I have put a few tidbits up on academic.edu, if you’re so inclined. And there will, eventually (but when??), be some more substantive contributions on this very page that is so useless currently. Honest, there will . . .
The Spreadsheet
Underpinning any archive is a spreadsheet. The one on this page was begun twelve years ago and is still being corrected, changed, and supplemented. That process will continue, and if you plan to revisit the archives or these web pages, please check back at each visit; very possibly a new version will have been uploaded by then. The file is always dated, right at the start of the filename; thus this one is called “2020_12_30_WWI_sheet_music_website.”
Please download it and manipulate it however you want: sort, filter, reorder columns, rename, add notes—anything that will be useful for your purposes. It is your tool to use for your research, even if your objectives are largely independent of the image and metadata archive.
Most of the information is straightforward and the layout, obvious; but it might help to provide a very few explanations, nonetheless.
Scope and contents
It must be emphasized that this spreadsheet contains information only about digitized copies of sheet music. There are surely dozens—in some cases, hundreds—of copies of a particular title that reside physically in libraries across the country. No attempt has been made to locate or view these.
It follows that when a title appears in several editions, printings, or variants (for definitions of these, see the “Conventions”), the order of these is usually speculative. That is, one or another of those physical copies might indicate that the “2nd printing” is actually the “3rd printing,” because the physical copy postdates the copyright deposit but precedes the so-called “2nd printing.” The ordering is useful: it often indicates how long a title remained current, and it often tells us something about the performance history, about recordings or piano rolls, or about the changing historical context. But the ordering is not a proper exhaustive bibliography of publications; that task is not manageable at present.
The spreadsheet brings together the Myers and Driscoll collections; it is therefore useful for joint searches or integrated comparisons, since these would otherwise entail two different searches and multiple pages in the digital archive. But the spreadsheet also includes additional digitized copies found online at other repositories. These grant a more complete picture of the history of a particular title; they make research and conclusions more secure, bearing in mind the caveat about physical copies, above. Online collections are constantly being created or supplemented, and every few years a semi-systematic pass through the archive is made to discover new additions. The key point? Once again: nothing is complete or final.
Each row in the spreadsheet corresponds to a single item of sheet music. The rows are color-coded: yellow for items in the Myers collection, blue for the Driscoll, green for items that appear in both, white for items located elsewhere.
Columns A through J
Columns A (“Driscoll Identifier”) through J (“© register”) replicate—or should replicate—metadata that is (or will be) entered into the online archive. They are provided here to facilitate searching and filtering. For example, using the spreadsheet it is relatively simple to construct a list of the music issued in Boston, ordered chronologically: just sort the spreadsheet first by “Place” and then by “pub date” or “© register”. That would be well-nigh impossible using the search mechanism on the website. But the website search mechanism allows for different kinds of research—to locate all the titles that have anything to do with a “liberty loan” drive, for example. For more information about this, see the “User’s Guide.”
There is one small difference between the spreadsheet data and the metadata in the archive: if no copyright was registered, the archive line will read “no copyright registered,” but the spreadsheet enters the year followed by double zeros: 1917 00 00. (All dates on the spreadsheet are entered in this form—YYYY MM DD). This alteration helps to preclude sorting that would mix numerical and alphabetical entries.
Columns K through O
It is very important to understand that copyright in the 1910s proceeded in two stages: first someone registered copyright, and then someone deposited copies of the object being copyrighted. Two copies were deposited for published music, except for foreign publishers, who needed only to deposit a single copy. One copy was deposited for music in manuscript.
Under “details” (Column K) is entered, in short form, anything about the publication that helps to date or contextualize it.
An entry here normally begins with the date of the copyright deposit—for example, “2 c. 1918 03 07.” Most often this is within a few days of the registration (column J), but not infrequently the two dates are weeks or even months apart. In general, it can be assumed that music was not made publicly available until after the copyright deposit—and certainly not until after copyright was registered. (There are some notable exceptions, but this rule seems generally to hold.) Hence the timing of a publication—crucial when it is linked to current events—depends more on the deposit date than the registration.
The timing also depends on information that can be gleaned from details on the publication itself. Nearly all commercial publishers advertised other titles on the back cover, and sometimes on inner pages as well. These advertised titles are also noted in column J, together with their copyright dates. From the principle sketched above, it follows that a particular printing or edition must postdate the latest copyright date of all the music advertised. Consider by way of example a title that was issued in several versions—“Just a Baby’s Prayer at Twilight,” for instance. The copyright deposit was 1918 01 06; hence, all the versions postdate that day. But one version advertises “For the Two of Us” on the back cover. “For the Two of Us” was copyrighted on 1918 02 23; hence that particular version of “Just a Baby’s Prayer at Twilight” postdates 1918 02 23, over two months later.
From this information—and sometimes from details on the front cover or even, rarely, advertising history—an earliest possible date of appearance can be deduced. That date is recorded in column L (“earliest date”). Again, this is useful primarily because it permits the construction of an accurate longitudinal understanding of popularity: a title was only briefly popular (or not at all popular) and issued only in one form, or in forms that closely follow the copyright; or a title was popular over a long period, as evidenced by forms that can be dated months or years apart. The reason for the “earliest date” is given in column M, in shorthand: fc (front cover), bc (back cover), “2nd printing” (which presumably would follow the first by at least a day), and so forth.
The remaining columns are less complete, because detailed study of individual titles is still under way. Column N (“version”) contains a shorthand code or tag that helps identify recurring covers or inner pages. The number is of the edition, usually; letters taken from the front of the alphabet (a, b, c, etc.) indicate different front covers, in order of publication; letters in reverse order from the end of the alphabet (z, y, x, etc.) indicate different back covers; letters in the center of the alphabet (m, n, o, etc.) indicate different inner pages. And the final column, “order,” is a working hypothesis of the order in which different versions appeared.
For you (and me) to do
Again: this is not research; this is a tool for research. There is much that remains to be done. I, for example, would like to insert a column for cover artists, and I hope a future version of the spreadsheet will contain that. I also need to complete, edit, and clarify existing entries. And, as I noted, more entries will appear, almost certainly, with every web search that is done.
But you might want to do something very different—which is exactly why I offer you raw data, rather than a set of interpretations. My only request is that, if possible, you inform me of your discoveries and insights, particularly if these will enrich the spreadsheet (and perhaps the online archive) further. Public, open access to data makes us all collaborators—and that, in my judgment, makes the world a better place.
A tool for research
to accompany the digital archives
World War I Sheet Music from the James Francis Driscoll Collection of American Sheet Music
and the
James Edward Myers World War I Sheet Music Collection
~-~
Conceived, researched, and written
by
William Brooks
~-~
Archival metadata written, entered, and edited
by
William Brooks
~-~
Digitized images created
by
Newberry library staff, under the direction of
Jen Wolfe, Jennifer Thom, and John Powell
and by
University of Illinois library staff, under the direction of
M. J. Han, Angela Waarala, and Patricia Lampron
~-~
Initial inventory created
by
Newberry Library volunteers, directed by Douglas Knox
and by
University of Illinois Library School students, directed by Scott Schwartz
~-~
Funding provided
by
The Arts and Humanities Research Board
The Hampsong Foundation
The National Endowment for the Humanities
The University of Illinois
The Newberry Library
~-~
Special thanks to
Scott Schwartz, Patricia Lampron, M. J. Han, and Angela Waarala
at the University of Illinois
and to
Doug Knox, Jennifer Thom, Jen Wolfe, and John Powell
at the Newberry Library
~-~
all content © William Brooks
December 20, 2020
User’s Guide
to
the online version of
the Myers and Driscoll collections
of Popular Music of World War I
This brief guide is meant to facilitate research by persons interested in the culture of World War I and, in particular, the culture’s musical manifestations. The explanation below pertains to two online archives. These contain images of sheet music that are, of course, interesting and useful in themselves. But the presentation of these images and the metadata associated with them are meant to be a tool for research—a tool that can be applied in an indefinitely large number of ways to extract data, discover examples, and acquire new insights about the war years (taken to be 1914–1920) and the music created during and about World War I. That tool is best used together with a spreadsheet that contains much, but not all, of the metadata in a different form.
Each version of the metadata affords—and constrains—certain types of research. Neither the spreadsheet nor the explanation below is meant to impose research agendas or prescribe methods; they are intended simply to explain the capacities and peculiarities of the two versions, taken together, much like one might describe the attributes and potentials of a newly designed bread-maker. Please do create your own recipes.
The entry page
Browsing
Searching
The item pages
Envoi

The entry page
In all that follows, the Myers Collection will be used for illustration, and it might be useful if you opened the entry page for that collection now.
Figure 1, above, depicts that entry page; the Driscoll entry page is identical except that the descriptive text and image pertain to that collection. The top and bottom of the page are fixed as a header and footer that appear on all pages. The bottom gives links and details regarding the University of Illinois Library, the institution that houses both digital collections. The physical collections are, respectively, at the Sousa Archives and Center for American Music at the University of Illinois and at the Newberry Library in Chicago. Do note the contact information provided at the bottom, just above the blue footer; “contact us” opens an email link to write the library staff. If the website as a whole is perplexing or troublesome or prompts suggestions from you, those are the people to write; but if you have questions or, better yet, information about the sheet music and the metadata itself—about titles or individuals or publishers, for instance—it will more helpful for us both if you contact me, William Brooks, at w-brooks@illinois.edu.

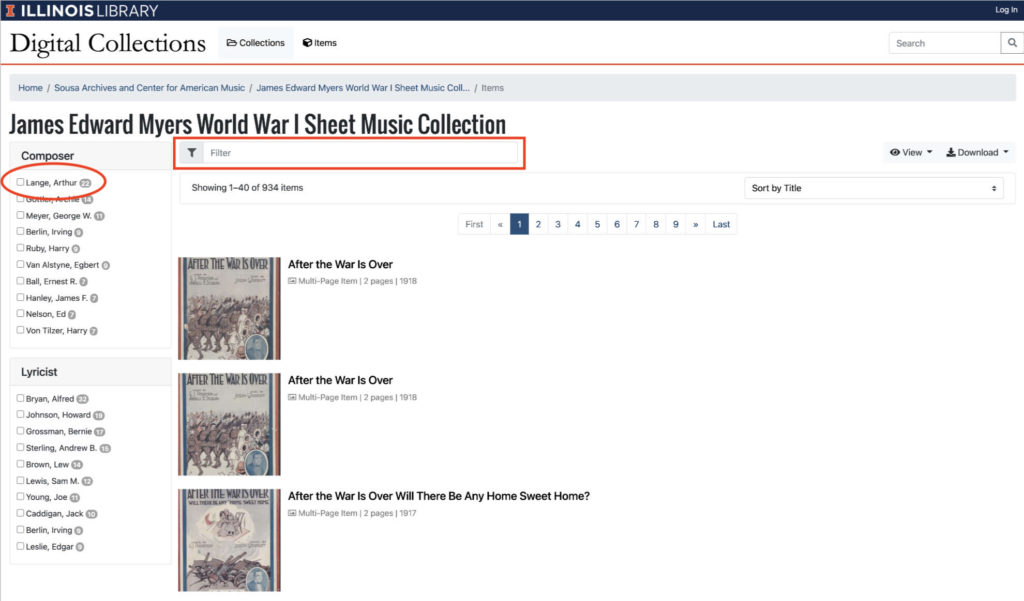
In the center of the page is a summary of the Myers collection, and above it there are two boxes (red rectangle in figure 2). The box on the right (“Physical Collection”) takes you away from the digitized collection and to the finding aid for the physical collection. This can help if you ever need to see a title in person; you can specify the exact location so that the archivist can retrieve the material in advance of your visit. The box on the left (“934 Items”) opens the collection in browsable form, discussed below. On the right, above the image, is a search box (red oval in figure 2) that applies to this collection only. Searching, too, is discussed below.
The top of the entry page, above the red line, identifies the Myers collection as part of the Illinois Library’s Digital Collections. Links on the left (green rectangle in figure 2) take a user to lists of all the collections and to all the items in the collections. It’s worth investigating those collections, since for certain kinds of research they will be useful. Click on “Collections” and enter “entertainment” in the filter box near the top on the left. The “American Popular Entertainment Collection” appears. This is an immensely valuable resource, and the three periodicals digitized there were current during the years when this sheet music was published. Now click on “items” and enter “clipper” in the same filter box; the most relevant items, the website decides, are the digitized issues of the New York Clipper, which was, before Variety, the trade journal for show business of all kinds.
Return to the entry page, if you would. Above the red line and to the right, there is a search box (green oval in figure 2). This box searches all the digital collections. The Myers collection is among these, but a search in this box for a common word or phrase usually produces an unmanageable number of hits. Try entering “after the war” (in quotation marks to ensure it is read as a phrase) in that search box. You will get something like 769,344 hits, which is not much use at all. But on the left there are a series of filters: names of collections, creators, subjects, repositories, and so forth. Now check the box, under “Subject,” next to “World War, 1914 — Songs and music.” Those hits are reduced to 36 items; and these are exactly what you would obtain if you searched the Myers and Driscoll collections separately for that phrase. Thus, with a little strategic filtering, the “Digital Collections” search box allows both sheet music collections to be searched at once. This is useful.
Now delete “After the War” and insert instead “Alcoholic Blues.” You will have 315 hits, and the first one is for a piece of sheet music in the Myers collection. But directly under it is an article from the New York Clipper for 8 October 1919. Remember the page number (14) and click on the link. You will be taken to the pages in the “American Entertainment Collection” for that particular issue of the Clipper. Find page 14, click on it, and then click on the advertisement that is highlighted. “Alcoholic Blues” is highlighted in a sentence at the bottom of the page: “Performers without exception claim it’s as big a song as ‘Alcoholic Blues.’” You’ve learned something: “The Alcoholic Blues” (which was copyrighted in December 1918) was so successful that in October 1919 its publisher was still using it as a standard against which to measure new publications.
Not all searches will be as efficient or as simple as that one. But the ability to combine sheet music, trade journals, and even newspapers or photographs in a single search, filtering as necessary to eliminate irrelevant results, can be a very powerful tool in discovering the historical context in which an item of sheet music—or a person or a publisher—is embedded. And that has only been made possible by placing the Myers and Driscoll collections in a field of digitized artifacts, all of which are treated entirely equally by a single search engine. [top]
Browsing
Find your way back to the entry page for the collection and click on the browse button (“934 items”). You are taken to a list of titles, each with a thumbnail image of its cover, and with a different set of filters on the left (figure 3). These work exactly as did the filters in the global search we did earlier; if you check the box for “Lange, Arthur” (red oval in figure 3) the number of titles listed is reduced from 934 to 22. This is equivalent to searching for the phrase “Lange, Arthur” or for the words Arthur and Lange (without any quotation marks). You can confirm this, if you wish, by returning to the entry page and entering those words in the search box above the image.
Browsing is straightforward; just work your way down the page, looking at whatever catches your eye. But at this point you may find it useful to download and open the spreadsheet, because certain peculiarities mean that titles are not treated quite alike there. First, the browsing page automatically disregards articles at the start of titles (“A,” “An,” “The”), as is conventional. Not so with the spreadsheet, which is distressingly literal about such things; hence “The Blue Star in the Window” on the browse page is “Blue Star in the Window, The” on the spreadsheet.
More importantly, the two platforms exercise different rules regarding punctuation. Excel (the platform for the spreadsheet) treats all punctuation as alphabetical characters, and orders entries accordingly. Thus, on the spreadsheet “America the Free” appears before “America, Here’s My Boy,” which appears before “America! My Homeland,” which appears before “America’s Crusaders,” which appears before “American Hearts.” In contrast, when sorting, the website disregards all punctuation including spaces; thus those titles would appear in the following order on a browse page: “America, Here’s My Boy,” “America! My Homeland,” “American Hearts,” and “America’s Crusaders.” This difference is usually of no consequence when browsing, but if a direct comparison is made between the spreadsheet and the browse page, it can cause confusion. And it has a more substantial effect when searching: for example, searches for “America! My” and “America, My” or “America My” give exactly the same results despite their different punctuation. [top]
Searching
On the entry page, searches are done using the search box. On the browse page, the terms are entered in the “filter” box on the left, above the thumbnails (red rectangle, figure 3). It is very important to realize that searches include all metadata, not just titles and personal names. Since lyrics have been entered for all texted music in the Myers collection (they are still quite incomplete in Driscoll), a search for a particular word will find all the items in which that word appears in the lyrics or in the title—or, for that matter, anywhere in the metadata. Hence the editorial entries under “comment,” “historical note,” and so forth are also searched. If one searches for “liberty loan” one finds a title with the phrase (“That’s a Mother’s Liberty Loan”), lyrics with the phrase (in “The U. S. A. Will Lay the Kaiser Away”), and a historical note with the phrase (for “Let’s Keep the Glow in Old Glory and the Free in Freedom Too”). This inclusiveness might feel like an irritation if you’re trying to find a specific item, but it is hugely useful if you are pursuing research into a topic, an icon, a quotation, or other concepts that were common to many contexts. Again: the metadata and the search mechanism is designed above all to further research, not to index materials for retrieval.
The search engine requires complete words; a search for <Calif> will not find appearances of <California>. But it does accommodate a wild card, indicated by an asterisk. Thus a search for <peace*> will locate 121 items that contain “peace” and 17 items that contain “peaceful.” Searches are Boolean, following modified conventions. Two terms entered without quotation marks are automatically joined by a Boolean “AND”; thus a search for the pair of words <Absence Solman> (with no quotation marks) yields titles in which both “Absence” and “Solman” appear in the metadata. There’s just one of those: “Absence Brings You Nearer to My Heart.” Quotation marks indicate phrases, in which both words have to appear in sequence; hence “Absence Solman” yields no hits whatsoever. The minus sign (actually a hyphen) indicates that a term must NOT appear in the metadata: the pair <Absence -Solman> produces the title “I Wonder If You Miss Me” because “absence” appears in the lyrics and Solman makes no appearance. Finally, a double pipe serves as a Boolean “OR”: thus the string <Absence || Solman> yields eight titles, some containing the word “absence,” others containing “Solman.”
Searches, in sum, are extremely powerful instruments that, properly used, can generate both data and historical insights. I encourage you to explore their potential, and to share your insights with others in the community of scholars. [top]

In coordinating the spreadsheet with the digital archive, the item numbers (columns A and B on the spreadsheet) are key. Each item number is unique, and since each appears in the metadata, entering an item number from the spreadsheet directly into the search box (figure 4) will generate exactly the associated image and metadata and no more. When working with a set of materials—for example, all the versions of a single title—use item numbers to keep things straight. Item numbers work both ways, too; one can extract the item number from the website metadata and then search the spreadsheet for that string. This is useful: for example, if a historical note indicates that the imprint being viewed is the third of four printings, and if you have questions about the other ones, the spreadsheet usually will provide at least some of the answers.
The item pages
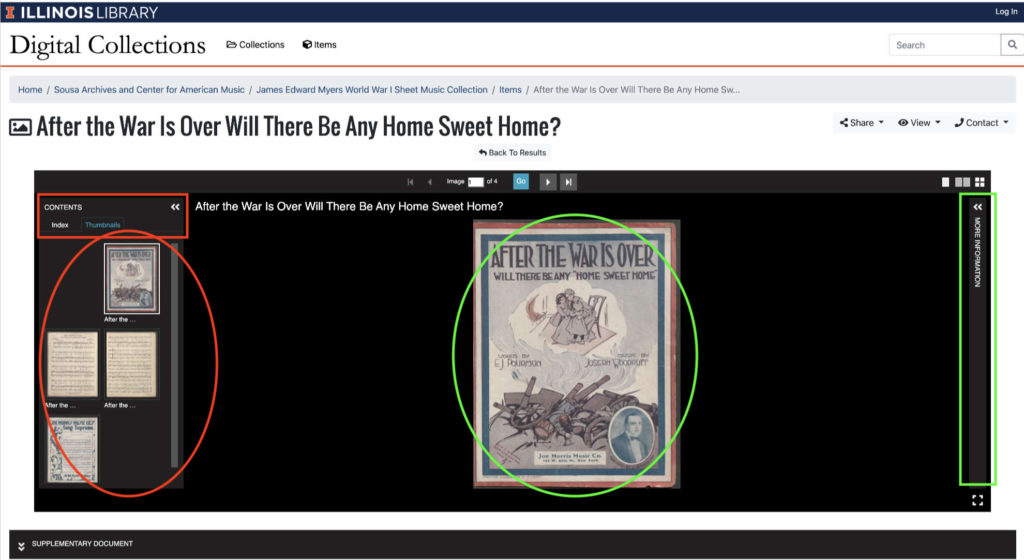
Try entering into the search field the item number from figure 4: 2014_12996_011. You should be seeing essentially the same page as figure 4 depicts. Now click on the thumbnail image or the title: you will see figure 5, or at least some portion of it. This is the item page, and all item pages follow a standard format. At the top are a set of images—thumbnails on the left (red oval on figure 5), the focal image on the right (green oval on figure 5). With the cursor on the focal image, try scrolling: this zooms in or out. Click and drag, and you can move the image as you wish within the window. Zoom in to see details—of the signature, bottom left, for example; zoom out to see the full image. Click on one of the other thumbnails and the focal image is replaced by that one. Explore the borders of the frame; these allow you to customize how much and what you are seeing. Information about the set of images appears on the left (red rectangle); metadata can appear on the right (green rectangle; click “more information”); tools for manipulating the image appear above the frame whenever your cursor rests in the window. Accessed in a bar just below the window is a “supplementary document”; this is a PDF transcription of the lyrics (see “History” for further explanation). Since the lyrics also appear in the metadata, you’ll rarely need to open this; but if you need to quote the lyrics at length, for instance, your task will be simpler if you download the PDF.

Scroll down the page a bit, and you will see something like figure 6. This is where the metadata appears; for a full discussion of the fields and their contents, see “Conventions.” You may have noticed that the the URLs for these pages—and all the pages in the digital archive—are quite long and not intuitive. The “Permalink” directly below the images (red oval, figure 6) allows you to copy the link with a single click (“copy”). Note particularly that certain entries have a magnifying-glass icon beside them (green ovals, figure 6). Clicking on these automatically searches the collection—just the Myers collection, in this case—for the metadata entered here. This is extremely useful when studying publishers or individuals, especially; you can very quickly see what other items in the collection are pertinent to the person or firm.

Now click on the green button (blue oval, figure 6), or just scroll to the bottom of the page and click on the plus sign next to “Download.” The page will open up and offer a range of download options. Each of these will serve a different purpose; the archival framework was designed in hopes that any user, needing an image for any purpose, would be able to generate an appropriate form of that image without having to employ a graphic design program post-download.
At the top (green rectangle, figure 7) are three options that provide a complete set of images for the entire item—four, in this case. “Zip of Masters” yields the four master images—extremely high-resolution and very large (in this case, over 2 GB). “Zip of JPEGs” provides just what it sounds like: four (in this case) separate images in JPEG format—good but not exceptional resolution. And “PDF” creates a single PDF file that contains all four images in sequence.
Below these are additional options for single pages (red rectangle figure 7). The two “master file” options are self-explanatory; but click on “Custom Image” for the top image (the cover page). A popup box appears, shown in figure 8.

This is a very powerful conversion tool, extremely useful if you need an image for a specific purpose. On the left a series of five boxes (red oval, figure 8) gives options for resolutions, from extremely high and large (100%) to very low and small. If one needs a super-high quality image—for use in a video, say, in which the “camera” will zoom in and in, smaller and smaller, to reveal tiny details—use the highest resolution. For a thumbnail used as a part of an index or catalogue, choose the lowest. And so forth.
But we’re not done! The boxes below (green oval, figure 8) allow you to convert the image, at the resolution you’ve chosen, from color (the default) to either bitonal (black and white) or gray (grayscale, in most printing circles). Are you publishing in a context that only accepts grayscale images? Then select “gray” at a good but not maximum resolution. Are you publishing a color insert in an edited collection? Then choose “color” and the highest resolution. And on and on . . . the intention is that the website will do the work for you, and you will be able to download precisely the image that you need. [top]
Envoi
And that’s it. We’ve discussed all of the options that this research tool affords. It remains only for you to use this tool—to test its limits, to explore its potentials, to devise unexpected applications, to . . . well, above all, to answer (and ask) questions. At the very bottom of the item page (yellow oval, figure 8) is a single, simple line: “Email curator about this item.” Click on it, and an email message will open, addressed to the Sousa Archives. The Archives will respond to you, of course, but they will also forward your message to me, because I want to know what you discover. I want to know your questions, your complaints, your confusions, and your triumphs. And if you want, you can bypass the Sousa Archives and write me directly: the address, again, is w-brooks@illinois.edu.
A world of insight awaits you. Enter that world, and enjoy all the creatures that inhabit it. They will be your playmates in what is, after all, a vast playground. Care for them—and for yourself. [top]
History
Beginnings
I could begin this narrative with an unspecified day in—I think—spring of 1964. I was in my junior year at Wesleyan University, and I had enrolled in a course in art song being taught by Ray Rendall, an extraordinary teacher and pianist. His method of teaching was simply to play the piano while the four students sang the song—usually several times. By the end of the semester we had made it into the twentieth century, and he devoted one class period to songs by Charles Ives—among them “He Is There!”. I was hooked: I borrowed the library’s copy of the 114 Songs and devoured every one. But it was the three war songs that lodged in my head, particularly Ives’s setting of “In Flanders Fields.” Seven years later, when I began teaching at the University of Illinois, I seized every opportunity to revisit those songs. My obsession with Ives and the music he wrote has never really waned.
But a more reasonable beginning would be early spring in—I think—2001. I had recently taken up my post at the University of York, and I was asked to offer a research seminar on a topic of my choice. I chose Ives; and I chose to look at the war songs in more depth, particularly with respect to material they quote and reference, and to its cultural and political implications. I continued work on my analysis over the next few years, and at some point I suddenly recalled that John Philip Sousa had also set McCrae’s iconic text. And I wondered: just how many settings had that text been given?
The British Library’s main offsite repository was at Boston Spa, a short drive from York. In fact, the university provided a shuttle service once a week, enabling researchers to use the facilities on site. In 2003—I think—I began to avail myself of that, spending most of each day literally turning the pages of the bound volumes that contained American copyright records. (Sometime later these were digitized and made available—for instance, on HathiTrust—and even now I use the digitized resource at least three or four times a week.) In June 2004 I assembled the first spreadsheet—by now there are dozens and dozens—of what would become, eventually, a much more comprehensive study of World War I songs. That contained a modest list of forty-three settings of “In Flanders Fields,” only a few of which I had actually seen. Work continued: I visited the British Library’s music copyright collection in London, where I viewed and copied some of these; I continued digging into library catalogues and other already-digitized sources to discover additional settings; and on August 28, 2005 I gave a paper on my findings—by then I had identified fifty-eight settings composed between 1917 and 1922—at the grandly titled Fourth Biennial International Conference on 20th-century Music, at the University of Sussex.
Initial resources
In the meantime I had applied for research leave from the University of York, with matching funds provided by what was then the British Arts and Humanities Research Board. My first application, in autumn 2004, was unsuccessful, but I reapplied the following year and was granted funding for a leave from early October 2005 through late April 2006. Those applications were focused on the “Flanders Fields” settings; but over the course of the past few years I had acquired a very undisciplined knowledge of the war years and had become especially interested in the transformations of American politics that took place between 1915 and 1920. I had begun to wonder if there were analogous transformations in popular music and the music industry, and I felt that I needed to broaden the scope of my research. And since I am more musician than scholar, I chose to pursue sheet music rather than labor history or the economics of music production.
Hence I applied for and received a Mendel Fellowship to spend two weeks at the Lilly Library at Indiana University, which housed an extensive sheet music collection assembled by Saul Starr. Starr, like Driscoll, organized his material by topic, so the Starr collection provided an excellent mechanism for extending my knowledge to the entire range of sheet music produced during the war years. In addition, the Lilly Library held a smaller collection assembled by Sam DeVincent, which I also incorporated into my research. Nearly concurrently I applied for a short-term fellowship at the Newberry Library, since I knew that the Driscoll collection would also be a fruitful resource to study. That application was also successful, and I was able to combine the two residencies into a single extended research trip during my leave in the spring of 2006.
At Indiana I compiled an exhaustive list of titles that Starr had categorized as related to World War I, expanding my Flanders Field spreadsheet tenfold. However, by the time I went to the Newberry I had developed some quite specific interests: in memorial music (building on my study of “In Flanders Fields”) and in different types of publishers and publications. (These interests persist, and they underlie two later publications, “The Rehearsal” and “Of Stars, Soldiers, Mothers, and Mourning.”) Hence my Newberry residency was devoted to detailed study of only a fraction of the collection—about a hundred titles—rather than to the compilation of a surface-level inventory. However, I was able to return for ten days in the autumn of 2006 and again in the summer of 2007, and I extended my lists somewhat more systematically then. By the end of 2008 I had cleaned and conjoined my many spreadsheets, and over Christmas I compiled the first of many combined lists—then containing not quite six hundred titles—with a very basic set of metadata categories and entries.
Towards digitization
In the spring of 2008 I was in the States for conferences and meetings, and I arranged to stop by the Newberry then. Indiana University was by then well on the way to creating a platform for digitized sheet music, and I had been tracking the work with considerable interest—in part because it would mean that I could continue working with the Starr and DeVincent materials even when I was in England. It seemed to me that the moment was right for the Newberry to undertake a similar project; and since the centennial of the war was only six years distant, I thought the place to begin was with the Driscoll Collection’s remarkable six boxes of World War I publications. I was introduced by email to Doug Knox, then in charge of digital initiatives, and he agreed to meet; in advance of the meeting, I drafted a brief proposal, to which he responded very positively. We both speculated about possible partners and funding, and I offered to have a conversation with the University of Illinois in about ten days’ time, when I would be on campus for a few days.
At the University I spoke with John Wagstaff, then head of the Music Library. We considered whether it would be possible to incorporate the library’s sheet music collection—which was arranged only by year of publication—into the digitization initiative that might soon be under way at the Newberry. I spent several hours making a very preliminary inventory of the boxes for the war years (1914-1919), primarily to determine whether they overlapped the Driscoll collection. The answer was mixed: since the library had aggregated many sources in building its sheet music holding, its character was less well defined than at the Newberry, where the collection clearly represented the tastes, judgments, and opportunities of a single devoted collector. On the other hand, for the same reason, the Illinois collection overall was possibly more diverse; there were, for example, a number of imprints from southern and Pacific coast states, which were largely absent from Driscoll’s holdings. I became aware that every collection was different, and that the right combination of collections would provide a rich inclusivity that collections amassed by a single personality might lack.
Over the next several months we collectively considered what collections might best complement each other. Our candidates ranged as far as the Harding Collection at the Bodelian in Oxford, but we eventually decided to construct a kind of Midwestern consortium: the Newberry, the Indiana collections that had already been digitized, the University of Illinois music library collection, and the holdings at Northwestern University. We began to investigate funding, and Newberry staff immediately thought of contacting the National Endowment for the Humanities (NEH), with whom they had had a productive and helpful relationship for many years. A few months later, Northwestern dropped out; but in the meantime, we had received very positive but informal feedback from the NEH. In the next round of funding, we decided, we would apply for a “Preservation and Access” grant.
An application—and again—and again
The application deadline was in mid-July 2009, so work commenced shortly after the start of the year. My contribution would be to draft or advise on most of the narrative sections; but before I could do that, we had first to firm up exactly what we were proposing. By then it was clear that incorporating the Harding collection would require funding of a different sort, perhaps from a pair of sources, one in each country. Matters became clearer in early February, when Indiana confirmed that they would happily permit us to include the sheet music they had already digitized but that they were working to capacity already and could not be an official partner in writing and implementing a new proposal. That left only the Illinois collection to consider, and so I arranged to be on the University campus for several days in April, during which time I planned to more systematically assess the importance of the holdings there. I concluded that Illinois probably had enough titles that were not found in either the Indiana or the Newberry collections to warrant building the Illinois holdings into the proposal.
However, it was impossible to confirm the necessary arrangements with the University in the time that remained; thus the proposal we submitted in July asked for funding to create “a searchable, browsable, curated virtual digital sheet music collection gathered around its focused theme of World War I” by making available “on-line digitized images of the published music associated with the Great War that is held in three major sheet music archives, the James Francis Driscoll Collection of American Sheet Music at the Newberry Library, and the Starr and Sam DeVincent Collections at Indiana University.” We noted that we anticipated “including items from Urbana in a subsequent phase of the project” and that, with the addition of those items, the collections together would contain “an estimated 3,500 distinct items—about two-fifths of the music related to the War and published during and immediately after it.”
And then we waited, as one does. Eventually, on March 10, 2010, we learned that our application had not been successful; and on March 30, we received the comments from the four reviewers. Two of them had given the proposal the highest rating; the others had ranked it a notch below. A recurring issue seemed to be the uncertainty regarding the Illinois collection: was Illinois a partner, or not? We resolved to resubmit the proposal in July for the 2010 competition, and a concerted effort was made to obtain a full commitment from the Music Library at the University. Separately and together, I, Doug Knox, and John Wagstaff had a series of conversations, and the upshot was that Illinois was indeed a full partner in the revised proposal—and, indeed, made a tangible commitment of funds and personnel to digitize the items in their collections. In effect, they provided a sub-proposal as part of the larger project that the Newberry would oversee.
But there was an additional consequence. In a conversation in early March, John Wagstaff remarked to me that the Myers Collection—held in a different location both administratively and geographically—had recently been accessed and conserved, and he suggested that I have a look at that as well. I wrote Scott Schwartz, the Director of the Sousa Archive and Center for American Music (which housed the collection), and in late March I began studying this new resource. It was immediately obvious not only that the war-related holdings exceeded those in the library’s collection but also that the arrangement Myers had imposed made this collection far easier to work with. By mid-June I had completed a preliminary inventory of the collection, and my spreadsheet had increased by half. We had sufficient data to include both the Myers and the library collection in the sub-project that Illinois was preparing. So, on July 15, 2010 the new, revised proposal was submitted to the NEH—but the “searchable, browsable, curated virtual digital sheet music collection” now included “an estimated 2,600 items digitized from World War I items in the Newberry Library’s Driscoll Collection, Indiana University’s DeVincent and Starr collections, and the James Edward Myers Collection and American Sheet Music Collection at the University of Illinois.”
And then we waited. While we waited, I completed the Myers inventory, in a short visit in early November. Volunteers at the Newberry filled in missing information—and the remaining titles—in the spreadsheet I had built for the Driscoll collection. And I gave a paper at the annual conference of the Society for American Music, in which I made extensive use of the data captured in my spreadsheets thus far. In 2011, the federal government had another budgetary meltdown, and March 2011 came and went without any news. And then, on April 22, we got the word: no funding for us. In May, we were sent the comments from the five panelists. Four of them had only praise and gave the application top ratings, and the fifth, though expressing some reservations about editorial criteria and policy, agreed to a top rating after discussion. Yet the panel as a whole dropped the project a single notch—just enough to sink it. However, there were consoling words about an “exceptionally competitive grant cycle,” and we already knew that funding overall had been substantially reduced, so we decided to again resubmit the proposal for the next round.
The version submitted in July 2011 was substantially augmented by illustrations of the kind of editorial data that would be captured and extracted for use by scholars. We felt we had addressed all the objections the panelists had raised, and we were cautiously optimistic about this, the third iteration. But then, in November 2011, Doug Knox accepted a new position in the Humanities Digital Workshop at Washington University in St. Louis. Moving into his place at the Newberry would be Jennifer Thom, an excellent cataloguer and—as it proved—an exceptionally collegial collaborator. But Jennifer, unlike Doug, had as yet neither demonstrated expertise in digital scholarship nor a history of successful projects that had been funded by the NEH. I expected the project to be denied funding for a third time, and in April 2012, my expectations were fulfilled. There seemed no point in requesting the panel’s comments; clearly the project—at least in the form that had been developed over the past four years—was dead in the water.
The Illinois initiative
Back at Illinois, Scott Schwartz expressed sympathy for the outcome of our application, but—more importantly—suggested that there might be a way to implement the concept on a much smaller scale, working only with the Myers materials and drawing on internal sources to fund the digitization. At the end of May Scott met with the Library’s Digital Content Creation Unit and outlined the scope and requirements; the response was positive, although at that point it appeared the Unit’s own funding would only cover about half of the costs. The conversations continued at a leisurely pace; both Scott and I were preoccupied with other projects, and changes in personnel and funding at higher levels in the University made consistent planning difficult. But near the beginning of 2013, Scott began to consider the ways in which the Sousa Archive and Center for America Music might mark the centennial of the war. An online exhibit drawn from the Myers collection was an obvious possibility, and so planning for digitization took on a new urgency, facilitated by a modest grant the Sousa Archive had received and by my plans to apply for external funding in 2014.
In the meantime, of course, I was still teaching at the University of York, and I too was making plans to mark the centenary. These entailed teaching an undergraduate module in spring term 2015, during which the students would plan and produce a three-day conference on music of the war years, replete with performances, student papers, and a poster competition. I approached two Illinois colleagues and friends, Gayle Magee and Christina Bashford, to see if they were willing to give keynote papers and serve as judges for the poster competition. They were delighted, and Gayle almost immediately suggested that a parallel conference take place in Illinois at roughly the same time. We quickly settled on the dates: February 26-28, 2015, at York, and March 10-11 at Illinois. Thus began a collaboration that eventually produced seven lectures at professional and public events, with Laurie Matheson, Justin Vickers, and Geoffrey Duce participating as performers, and Over Here, Over There, an edited, transatlantic collection of essays on war-related music published by the University of Illinois Press in 2019.
The Illinois launch
During the latter half of 2013, I continued checking and entering information on my Myers spreadsheet in anticipation of the digitization that would soon begin. Discussions about the metadata—what to include, how to present it, and the limitations and capacities of the platform—began in earnest at the start of 2014. At that time, all digitization at Illinois, and also at linked institutions elsewhere in the state, was managed though membership in OCLC and its content-management system, called ContentDM. I had expressed the view that including the first line of the lyrics, as is often done, is not necessarily helpful in many instances. I had proposed instead that a set of keywords be generated from the lyrics; but this was correctly met with the objection that deciding those constituted an inappropriate level of editorial intervention. The ideal solution would be to have the entire set of lyrics entered into the metadata, but ContentDM did not allow for that. As a result, we chose to provide a transcription of the lyrics that would be provided on a PDF as part of the images for each item and that would themselves be searchable. During the spring and summer of 2014, a team of students and interns directed by Scott Schwartz accomplished these transcriptions, and they were duly added to the images as the individual items were scanned.
At this time, too, I had planned to have a parallel website that would provide additional information about many of the metadata entries—short biographies for composers and lyricists, short histories of music publishers, explanations of dedicatees, places, and military units, historical background for musical styles and quotations, and so forth. That moved forward for about four months and then was derailed when staff moved on or were reassigned. In the end, that plan was abandoned, although I still hope to provide that kind of information in the future, as time and resources permit.
By the end of July the spreadsheet and the transcriptions were complete and a set of identifiers had been assigned to each item, keyed to the spreadsheet. The physical copies had been extracted and conserved, and scanning began. Scott was planning an official launch of the online collection, together with a physical exhibit of some of the titles and an inaugural lecture, all for Armistice Day (November 11), 2014. I agreed to deliver the lecture, and scanning started in earnest in late August. The lecture and the physical exhibit took place as planned, but last-minute issues with ContentDM delayed the official launch of the digitized collection until November 17. But on that day a press release went out, and Scott sent a general message to the entire University community: “Over the past year the staff of the Sousa Archives and Center for American Music have been working with William Brooks and the Library’s talented DCC, Content Access Management and Metadata crews to digitize the WWI sheet music contained in our James Edward Myers Sheet Music Collection and make it available as a new ContentDM resource. . . . The James Edward Myers World War I Sheet Music Collection can be accessed via the following URL: [http://imagesearchnew.library.illinois.edu/cdm/landingpage/collection/myers]. I hope that you will take a couple of minutes to visit this site and dig deeper into the rich content of this new ContentDM resource, and if you know of others interested in learning more about how WWI was reflected through America’s music, that you will recommend this resource to them.”
The Newberry initiative
While the Illinois collection was being readied for digitization, I was seeking funding. To support the digitization of the Myers collection, I applied for a Hampsong Education Fellowship; to work further with the Driscoll collection, in the hope that digitization was still possible, I applied for a long-term fellowship at the Newberry Library. Both applications were successful, as I learned at the start of 2015. The Hampsong Fellowship award was matched by the Sousa Archive and applied directly to cover the Archive’s share of the digitization costs. The Newberry fellowship meant that I would spend seven months—from December 2015 through June 2016—in residence, although in practice I planned unofficially to begin work as soon as possible (during a short stay in November) and continue on through the summer months. But even before then—indeed, within days of receiving confirmation of the award—I was in contact with Jennifer Thom about the implications and costs associated with creating an online archive, parallel to the one at Illinois, from the relevant Driscoll boxes. In meetings in February 2015, the Newberry agreed to fully fund that effort, with a team headed by Jennifer Thom and Jen Wolfe.
However, since our final grant application in 2011, the Newberry had dropped its subscription to ContentDM and was using a different system altogether. One immediate question, then, was whether the metadata fields at the Newberry would be compatible with those at Illinois. Over the next two months, a series of three-way conversations produced a solution: Illinois would host the images and metadata from the Newberry collection, although the Newberry would retain the rights and would have ultimate managerial authority. Scanning then proceeded, guided by my current spreadsheet for the collection, which was still somewhat skeletal in many respects. By the end of September 2015 the job was done, and the files were loaded onto a hard drive that was then shipped to the Sousa Archive.
By then, however, Illinois had also abandoned ContentDM and built its own management system, named Archon. All the digitized collections were being gradually migrated into the new system, and it made no sense to enter the Driscoll files onto a platform that would soon be obsolete. So the hard drive was left in storage until the Myers collection had been transferred, which took nearly two years. On the other hand, Archon had important advantages over ContentDM. It provided an elegant and rich set of alternatives for viewing and downloading images, and the search mechanism was unusually powerful and inclusive. Most importantly, for this project, was its capacity for metadata: the number of fields was virtually unlimited; each field could consist of a series of separate lines; and each field could accommodate a very large number of characters. Thus, for example, the lyrics could be entered in full in a single field; thus also descriptions and historical information could be as complete as the community of scholars could make it.
Work installing the Driscoll images began in earnest in June, 2017, but two months were required before various technical matters could be resolved. In the meantime, I had somewhat updated my spreadsheet, and I used it to assign identifiers to each set of images, item by item. With these in place, the images and metadata could be transferred into the Archon environment. That proved to be a painstaking process; efforts to automate it were unsuccessful, and most material had to be entered by hand and checked by several different people. During the course of this, various problems emerged with the images themselves: pages were omitted or duplicated; incorrect orderings for pages had to be corrected by hand; and a number of titles had somehow been overlooked during the 2015 scanning process. These errors are still being discovered; a task for the immediate future is to check every item systematically for completeness and correctness. Over the summer of 2018 a series of checks and corrections were done by key people—myself, Angela Waarala, and Patricia Lampron—and on August 15, the job was done: the Driscoll collection was live.
Summary
A path through a field of research is rarely smooth, and nearly always obstacles, detours, and reversals are encountered. But the path that created this research tool—this double archive to which I’ve given the umbrella title “Popular Music of World War I”—has been especially fraught. Many ambitions have been abandoned—or, more properly, deferred—but the result is still a more powerful tool that has great potential to yield unique data about composers, publishers, cover artists, lyricists, dedicatees, historical contexts, and on and on. It is simply to sketch those potentials that this guide—and this history—have been written.